 [Pwn2Win 2016] [Forensics 80 – Samuel Riff Breese] Write Up
[Pwn2Win 2016] [Forensics 80 – Samuel Riff Breese] Write UpDescription
We are presented with a PNG image file which is hidding top secret informations from mister Riff.
Question: the flag will be XXX (Upercase)
Resolution
Introduction:
At first sight the title was about Samuel “Riff” Breese.
When you talk about Riff, you’re usually talking about audio, and more generaly about WAV files : Wikipedia – WAV/RIFF.
We were pretty sure we were going to have to create a wav file at some point and we started looking for the WAV header datas.
Looking for the datas:
The file looked like a full black picture.

By looking at the actual pixels values (not their color representation, which is black) we saw that they aren’t all the same.
Creating a new image where the pixel value become the pixel color allowed us to distinguish interesting information:
 Have you seen closely enough? Yes, that’s text, tiny tiny text.
Have you seen closely enough? Yes, that’s text, tiny tiny text.
Looking the remaining time, there was only 6 hours left … Time to grab a pencil and papers!
..
..
..
Nooo, just kidding :p
Getting the datas, the right way:
We had a picture, but not a very clean one and OCR won’t like it very much.

First step was to try to make it look nicer.
From the initial file, we generated a bunch of this file with a slit variation of the threshold value that will decide if the pixel will be black or white.
def enhance(filepath,value):
im=Image.open(filepath)
pixdata=im.load()
for threshold in range(64):
img = Image.new("L",(im.size[0],im.size[1]),255)
pixdata2=img.load()
for y in xrange(im.size[1]):
for x in xrange(im.size[0]):
if pixdata[x,y] >threshold:
pixdata2[x,y]=255
else : pixdata2[x,y]=0
img.save('enh_%i_'%threshold+filepath)
The result was 64 images to chose from.
We selected the file #38 (anything around 35-40 has a good quality too) because letters/numbers were not overlapping and well outlined.
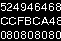
Second step was to separate this files into lines of text in order to feed the OCR.
The OCR works better with big pictures, so we also had to increase each line.
PIL offers several ways to do it, we tried some of those and checked which one gave us the best result:
def enhance_image(filename):
methods=[Image.ANTIALIAS, Image.BILINEAR, Image.BICUBIC, Image.NEAREST]
for method in methods :
image_name=increase(filename,4,method)
txt=image_to_txt(image_name,1)
print "method %i - len : %i - error:%i"%(method,len(txt),txt.count(' '))
![]()
Image.BICUBIC offered the best results, we used this one.

We cut the file into lines, upscaled it a little bit and stored it into a bmp file which we used with ‘tesseract’ from the shell.
def cut_image(filepath,size=14):
im=Image.open(filepath)
pixdata=im.load()
for i in range(3374/size):
img = Image.new("L",(im.size[0],size),255)
pixdata2=img.load()
for y in xrange(i*size,(i+1)*size):
for x in range(im.size[0]):
pixdata2[x,y-(i*size)]=pixdata[x,y]
img.save('%i_'%i+filepath[:-3]+'bmp')
increase('%i_'%i+filepath[:-3]+'bmp',4,Image.BICUBIC)
return i
In order to help our OCR, we just created a rule telling it to look only for hexadecimal values.
def image_to_txt(base_filename, number_of_files):
for i in range(number_of_files):
filename='%i%s'%(i,base_filename)
output='myout%i'%i
args = ['tesseract', filename, output,'/opt/local/share/tessdata/configs/justhexa'] #limiting the possible chars to 0-9A-F
proc = subprocess.Popen(args)
return 1
Improving data:
At this moment we had 241 files, each one corresponding to a line of text.
We have concatenated all the files and … nothing! There was lots of mistakes, we had to clean it again //ocr <3 🙁
-Comments are in the code-
def make_final_file(filepath='',datas=''):
if datas=='':
f=open(filepath,'rb')
datas=f.read()
f.close()
#First problem with Tesseract, we sometimes have 'blank' instead of a char
#looking at it closely, we can see that most of the times it read badly a '7'
#some times it also miss a '0' in '808' series
for j in range(len(datas)):
if datas[j] not in '0123456789ABCDEF':
if reponse[j-1]=='8' :reponse=reponse[:j]+'0'+reponse[j+1:]
else : reponse=reponse[:j]+'7'+reponse[j+1:]
#Second problem. Tesseract sometimes miss a char or discover 2 chars instead of one
#As we will have to convert it to hexa values, adding 1 char create a huge problem for us as it changes all the datas
#We have a lots of 80, which is 0 in a wave file (no sound).
#we will use these to identify and correct bad alignement of text and minimise problems (thew not solving them totaly)
out=""
offset=0
for i in range(len(datas)/2-6):
if datas[i*2-offset:i*2+6-offset]=="080808":
out+="00"
offset+=1
else : out+=datas[i*2-offset:(i+1)*2-offset]
#writing it to a file, just in case
f=open('rawoutput_texte_corrected.txt','wb')
f.write(out)
f.close()
#creating our final WAV RIFF File
hex_data=binascii.unhexlify(out)
g=open('rawfile4.wav','wb')
g.write(hex_data)
g.close()</pre>
We finally have our wav file.
Not very nice isn’t it? OCR may have mixed few values!
That was not a big deal in the sound’s data, but it could be if the header is messed up.
We took the wav file in a hex editor, and checked at the header (compared to the first line of text)

(Source: http://soundfile.sapp.org/doc/WaveFormat/)
Once the header was corrected, it was only necessary to adjust the file length and the data length chunk.
That’s all! We tried to listen the flag again!
We still don’t heard the flag! 🙁
They warned us that the flag had to be in uppercase, would they have screamed?
But wait… these bips were pretty familiar:
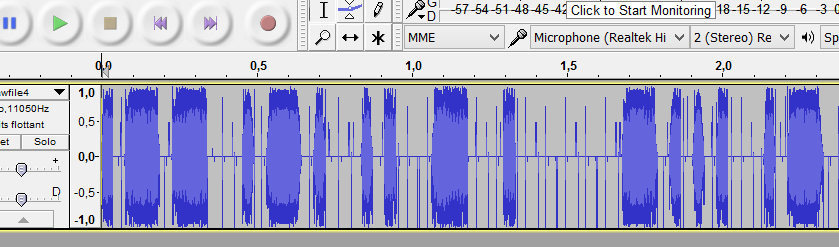
We just needed to traduct this in morse code : Wikipedia Morse code
{kind=link}
WRITEBAZINGATOGOON
Flag was : CTF-BR{BAZINGA}