 [Trend Micro 2015] [Analysis-other 100] Write-Up
[Trend Micro 2015] [Analysis-other 100] Write-UpDescription
Category: Analysis-others
Points: 100Please fix the PDF file for me.
Resolution
If you already tried to look at the PDF specification, you should know it’s a real mess. There are different versions of the format (PDF1.3, PDF1.4, PDF, 1.7 and certainly others). The format is very loosy, it means that we can do weird things without breaking the PDF file, but as a consequence it’s difficult to read the internals of the file.
Moreover, none of us were used to play with PDF specifications, so it was quite difficult, but we did it, and it was really interesting 🙂
Anyway, the goal of this challenge is to fix the PDF. Most PDF browsers are unable to open the file, there must be something missing. In order to check what can be missing, we could try to read it with Origami framework and other tools.
$ pdfsh Welcome to the PDF shell (Origami release 1.2.6) [OpenSSL: yes, JavaScript: no] >> PDF.read 'fix_my_pdf.pdf' [info ] ...Reading header... [info ] ...Parsing revision 1... [error] Breaking on: "stream\nx\x01\xED..." at offset 0x1581 [error] Last exception: [Origami::InvalidObjectError] Cannot determine object (no:13,gen:0) type [info ] ...Parsing xref table... [info ] ...Parsing trailer... [info ] ...Propagating types... ---------- Header ---------- [+] Major version: 1 [+] Minor version: 3 ---------- Body ---------- 5 0 R ContentStream 6 0 R Integer 3 0 R Page 7 0 R Resources 8 0 R FormXObject 9 0 R Integer 10 0 R Dictionary 11 0 R ImageXObject 12 0 R Integer 14 0 R Integer 17 0 R ImageXObject 18 0 R Integer 19 0 R ImageXObject 20 0 R Integer 15 0 R ExtGState 16 0 R Array 4 0 R PageTreeNode 21 0 R Catalog 2 0 R MetadataStream 22 0 R Integer 23 0 R ByteString 24 0 R ByteString 25 0 R ByteString 26 0 R ByteString 1 0 R Dictionary ---------- Trailer --------- [*] /Size: 27 [*] /Root: 21 0 R [*] /Info: 1 0 R [*] /ID: [ <<<4A35CD9A9BEE822FD415DF26633E5E4A&>>>; <<<4A35CD9A9BEE822FD415DF26633E5E4A>>> ] [+] startxref: 32548
$ pdfimages fix_my_pdf.pdf . Syntax Error (756): XObject 'Im2' is wrong type
OK, we have some errors, which could be our start point in order to begin the forensics : “Cannot determine object (no:13,gen:0) and ‘type XObject ‘Im2’ is wrong type” .
With these hints, we could open pdfwalker and try to search any object with ID 13.
By the way, quick explanation of the PDF format, before moving on. When you load a PDF, you actually load some objects which have properties. For example (as you’ll see a bit later), you can load a FormXObject which is a container for other objects. This FormXObject has properties, for example the length (/Length), the compression level (/Filter), the object type (/Type), etc. But it’s not as simple as it seems : properties have values which could be literals… or object IDs, which adds an amazing mess 🙂
So, get back to our challenge. PDFWalker is launched, and we are looking for some object with an ID 13. We just have to look for “XX 0 obj” strings (in this case, maybe this string is not mandatory).”

In the screen above, the selected object is a FormXObject with an ID 8. We looked for every IDs, but there weren’t any 13. Nevermind, we still have another hint : “Im2”. Let’s look for it (Ctrl+F).

So, as you can see, there are two references. The first one (in the right corner), is in the FormXObject data, and the second one (on the left) is in a dictionary property. Let study them. The FormXObject is just a form containing other objects (as a div in html for example). These objects are in the Resources properties, and the value of this property is “10 0 obj”. By looking at this object (just double click on the “Resources” word), we can see that it is… our dictionary containing Im2. By looking at the dictionary, we can see the following properties :
10 0 obj << /ProcSet [ /PDF /ImageB /ImageC /ImageI ] /ExtGState << /Gs1 15 0 R >> /XObject << /Im1 11 0 R /Im2 13 0 R >> >> endobj
Im2 is referencing on object with the ID 13! Hmmm, seems correct, everything’s related 🙂
From now, we can sum up, without even opening the PDF with a viewer, that it contains a form at position 153:318-642-455 (see the BBox section of the FormXObject), and that this form contains a dictionary of two XObject with IDs 11 & 13. By clicking on the “Im1” on the left panel, PDFWalker shows us the object which is an ImageXObject. But, when we click on the “Im2”, an error message explains us that the object has not been found.
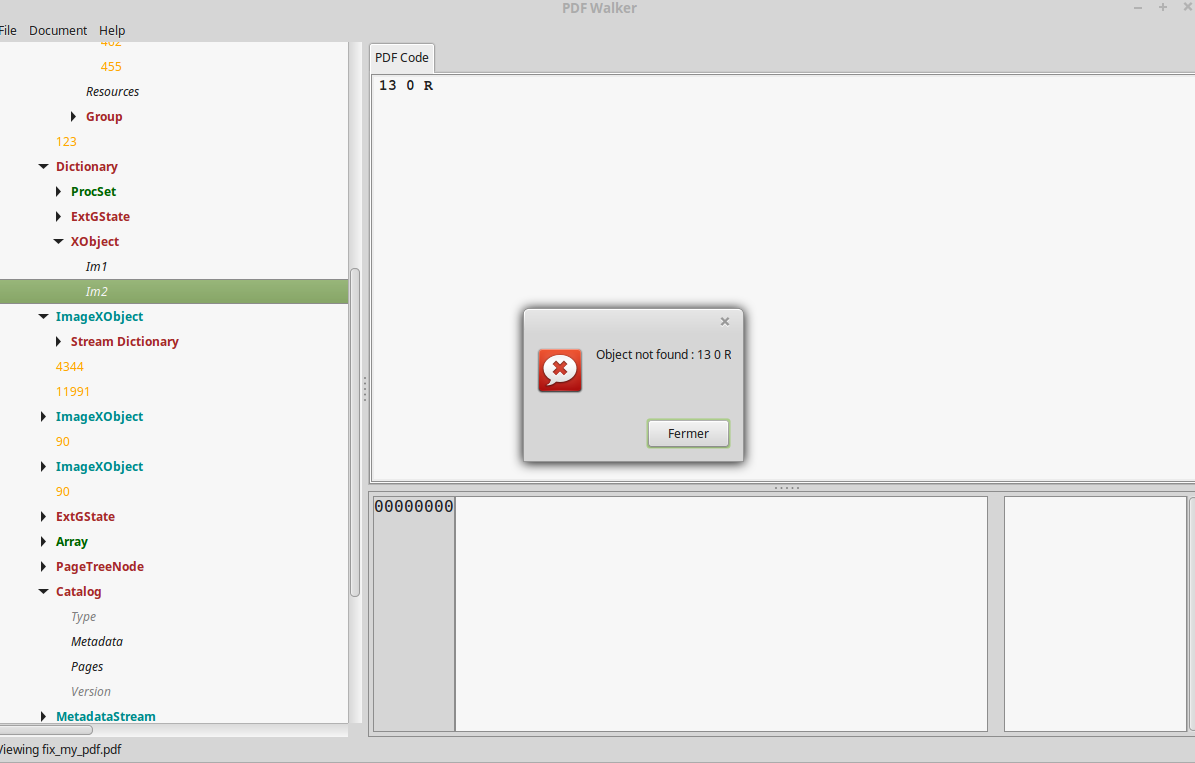
Now, it seems pretty clear that what we are looking for is the object 13. It MUST be somewhere. To find it, why not check with an hexadecimal editor ?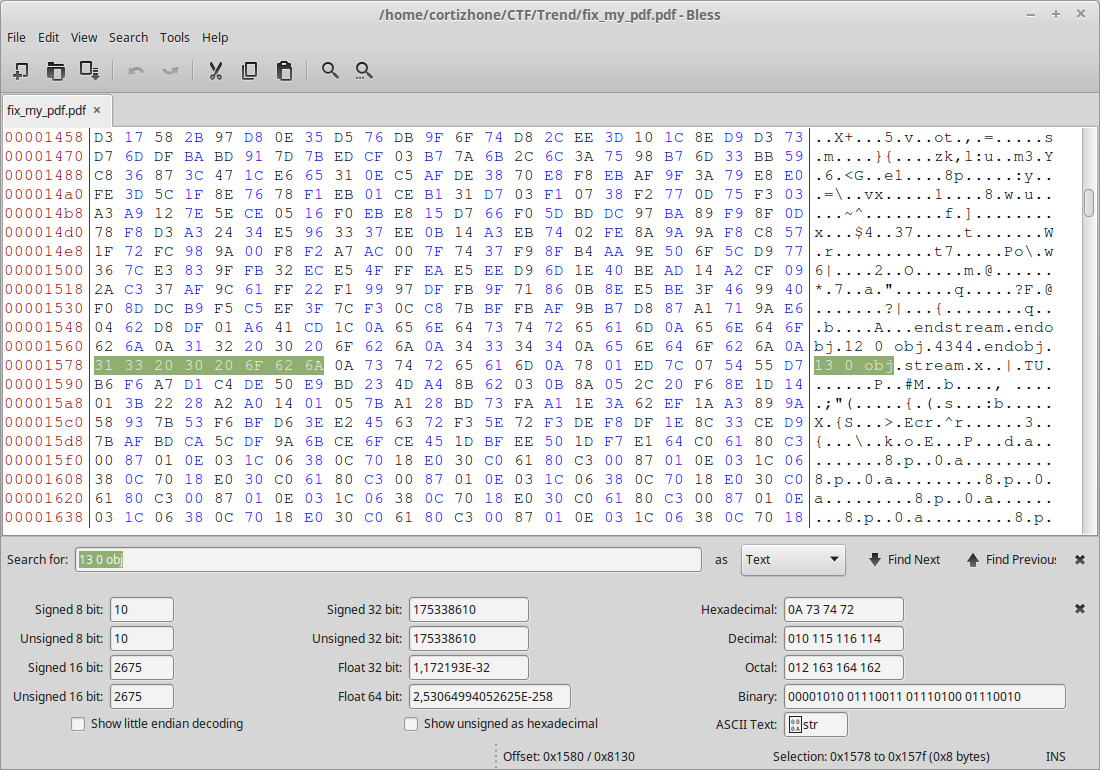
It’s just here, in front of us! But as pdfwalker didn’t find it, there must be something wrong on this part. The best way to find it is to check with a valid ImageXObject and by looking for object 11.
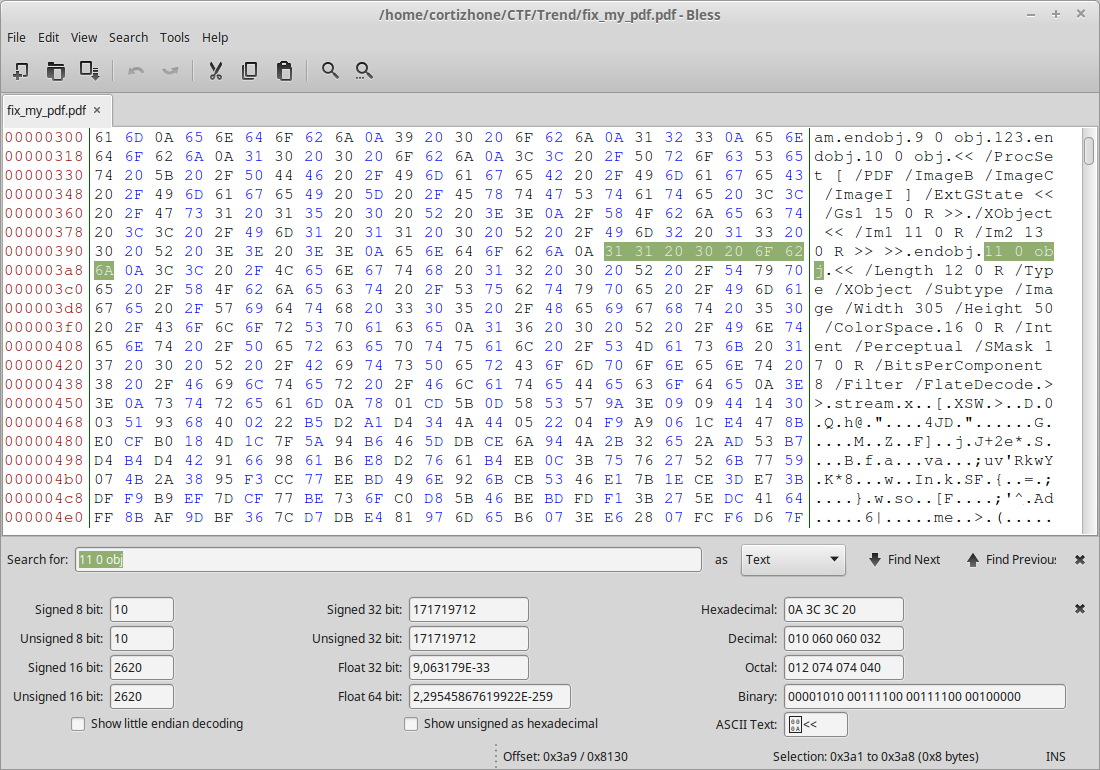
OK, now that we have a valid object, we have to check differences. For the 13 0 obj section, we have this :
endobj 13 0 obj stream
For the 11 0 obj section here is what we have :
endobj 11 0 obj <span style="color: #ff0000;"><< /Length 12 0 R /Type /XObject /Subtype /Image /Width 305 /Height 50 /ColorSpace 16 0 R /Intent /Perceptual /SMask 17 0 R /BitsPerComponent 8 /Filter /FlateDecode >></span> stream
It seems that we are missing some data for our broken object (differences are in red). As said before, PDF is a very loosy format, it means that, unlike some other files specifications (BMP for example), the data offset isn’t mandatory, as PDF viewer will parse the entire document to find object delimiters. The best way to fix the object 13 is simply to copy/past the missing part, just as shown below, and to modify the length reference (12 0 R is the length for ImageXObect 11, and during our research we saw that object 14 seemed to be the length for the ImageXObject 13)
endobj 13 0 obj <span style="color: #ff0000;"><< /Length 14 0 R /Type /XObject /Subtype /Image /Width 305 /Height 50 /ColorSpace 16 0 R /Intent /Perceptual /SMask 17 0 R /BitsPerComponent 8 /Filter /FlateDecode >></span> stream
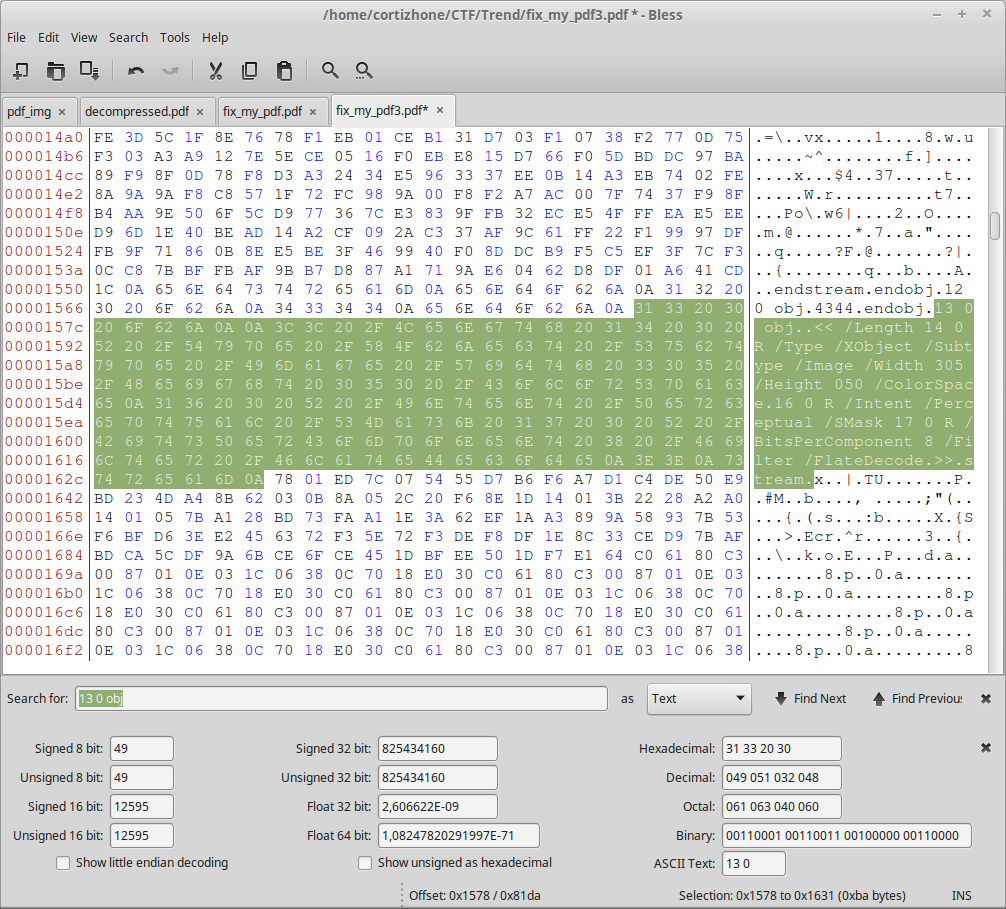
OK, file saved, we just have to test it 🙂

Well well well. Not so bad, but there is no flag here.
After some tests (actually a lot, during hours), we saw that changing the ImageXObect width and height was giving us some results. We doubled the values and opened the PDF again.

We’re almost done! There seems to be some text in the image, but changing again the width/height, didn’t worked. Maybe there is something else to change ? After all, there aren’t lot of properties. Why not try to change the BitPerComponent to 16 ?

FINALLY! The flag was in front of us! We did it!
Flag is TMCTF{There is always light behind the clouds.}
Here is the fixed pdf 🙂
As said at the beginning of the write up, none of us were good at PDF forensics, so it was really cool to solve this challenge and to learn a bit how PDF is working
External links :
These links were helpful to solve this challenge, but also to learn how PDF is working.
http://bt3gl.github.io/csaw-ctf-2014-forensics-300-fluffy-no-more.html
http://blog.didierstevens.com/
Enjoy
The lsd